|
I am the founder & CEO of Analemma, and also an assistant professor at SII. I received my Ph.D. in Computer Science and Technology from Fudan University in 2024, where I was advised by Xipeng Qiu and Xuanjing Huang. I had internships at Shanghai AI Laboratory (2023), Alibaba DAMO Academy (2022), and Amazon Shanghai AI Lab (2019-2020). My research interests are using post-training, especially reinforcement learning, to improve pre-trained large language models for various scenarios. Reach out to me over email: txsun@analemma.ai. Google Scholar / Github / Twitter / OpenMOSS |

|

|
|
Full list of papers can be found at Google Scholar / Semantic Scholar / DBLP / ORCID (*: Equal contribution) |
|
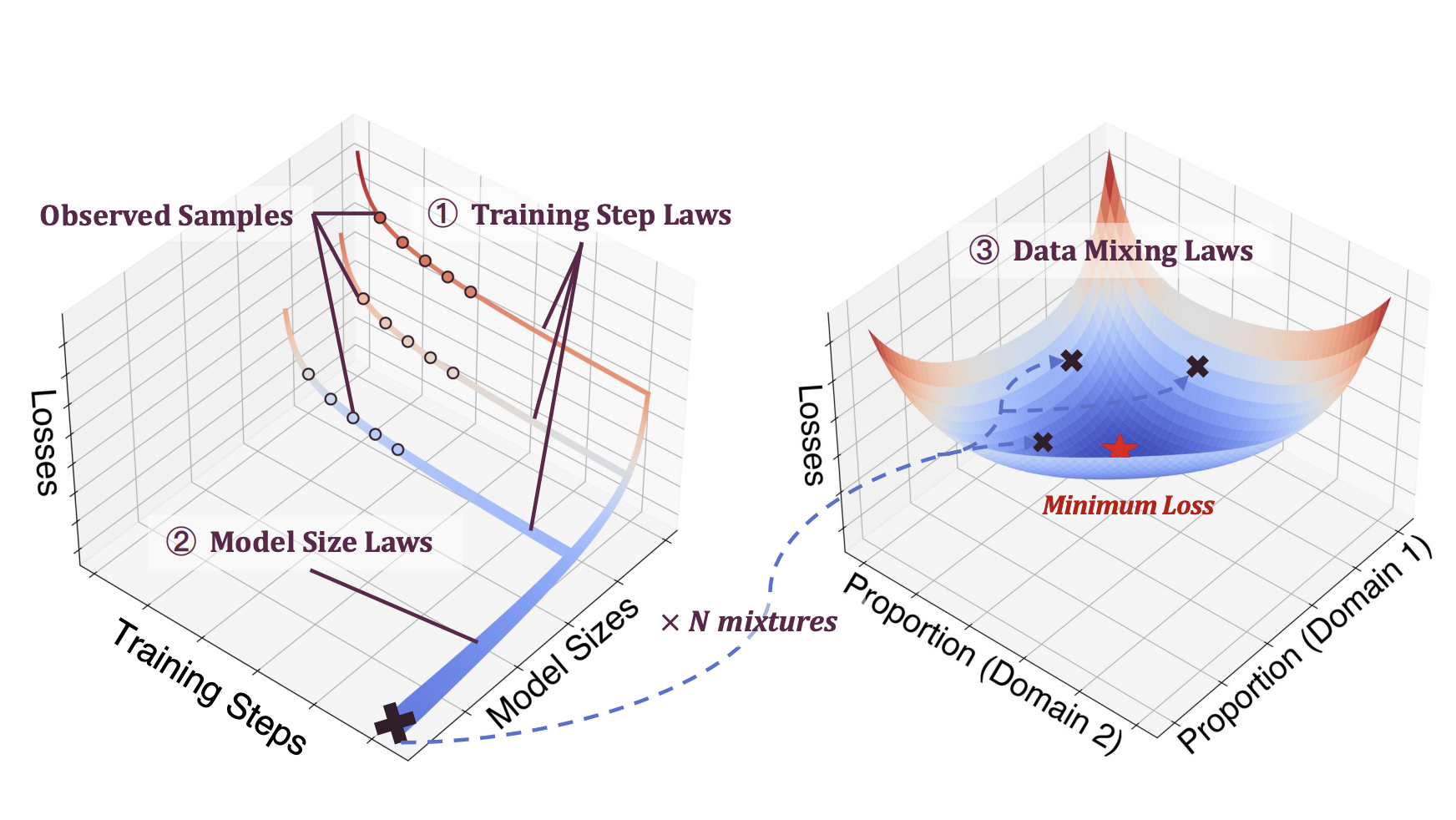
Jiasheng Ye, Peiju Liu, Tianxiang Sun, Yunhua Zhou, Jun Zhan, Xipeng Qiu ICLR, 2025 pdf / blog on OpenMOSS We discover the quantitative predictability of model performance regarding the mixture proportions in function forms, which we refer to as the data mixing laws. Fitting such functions on sample mixtures unveils model performance on unseen mixtures before actual runs, thus guiding the selection of an ideal data mixture. |
|
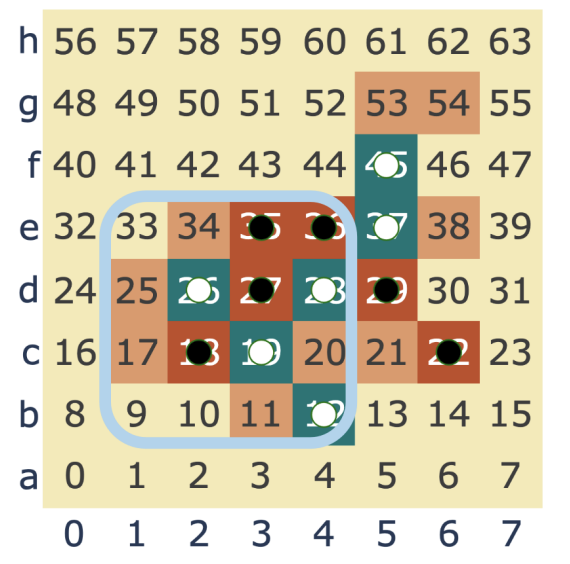
Zhengfu He, Xuyang Ge, Qiong Tang, Tianxiang Sun, Qinyuan Cheng, Xipeng Qiu arXiv, 2402.12201 pdf / blog on OpenMOSS Sparse dictionary learning has been a rapidly growing technique in mechanistic interpretability to attack superposition and extract more human-understandable features from model activations. We ask a further question based on the extracted more monosemantic features: How do we recognize circuits connecting the enormous amount of dictionary features? We propose a circuit discovery framework alternative to activation patching. |
|
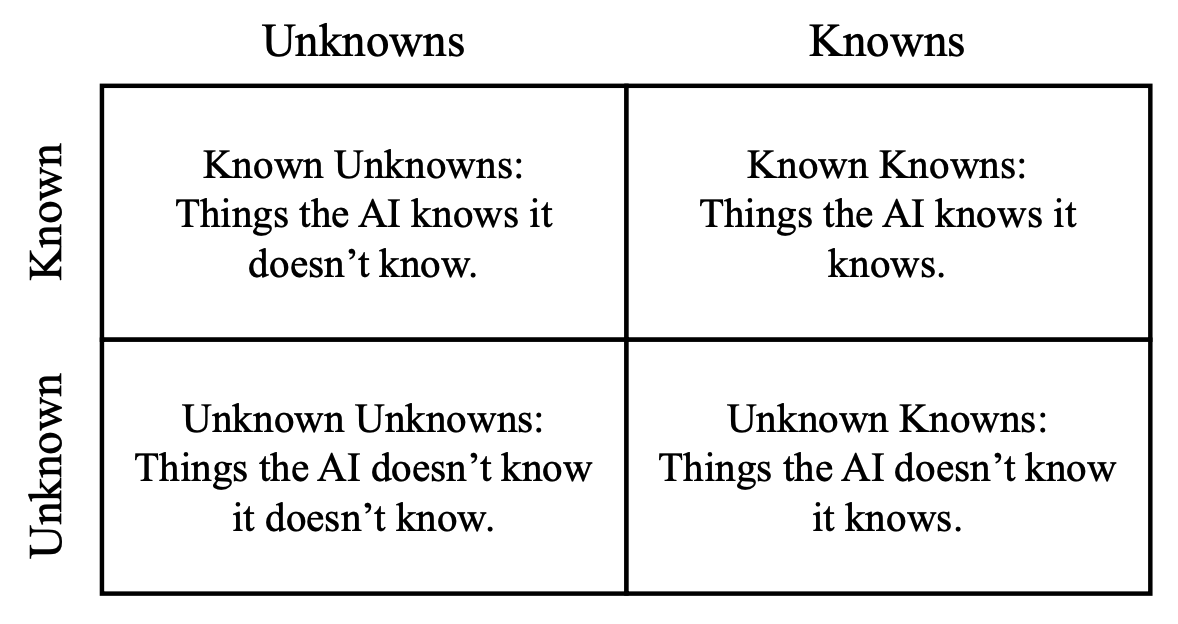
Qinyuan Cheng*, Tianxiang Sun*, Xiangyang Liu, Wenwei Zhang, Zhangyue Yin, Shimin Li, Linyang Li, Zhengfu He, Kai Chen, Xipeng Qiu ICML, 2024 pdf / code / blog on OpenMOSS We ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. |
|
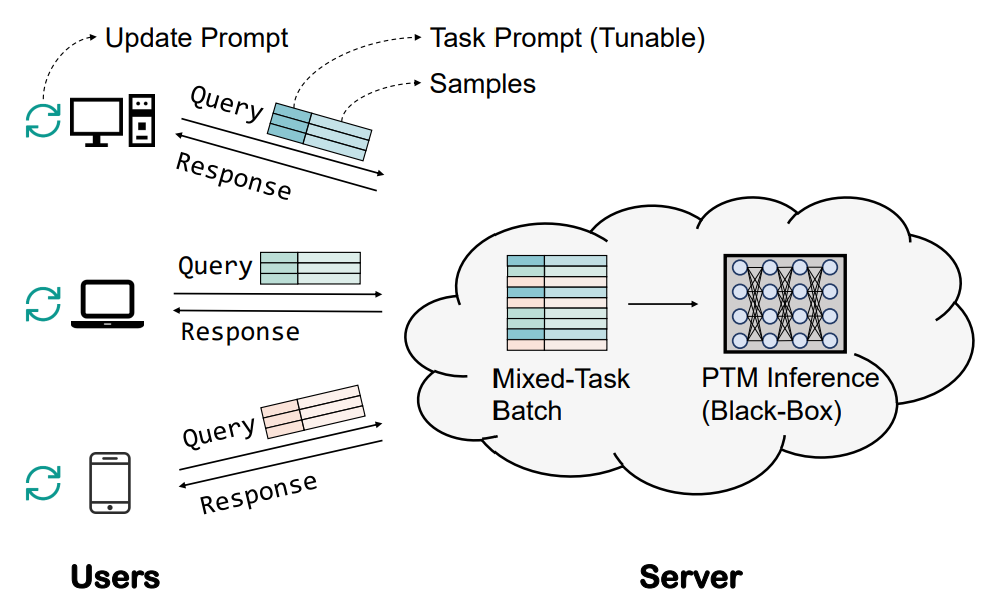
Tianxiang Sun, Yunfan Shao, Hong Qian, Xuanjing Huang, Xipeng Qiu ICML, 2022 (Spotlight) pdf / code / slides We propose a promising and practical scenario, Language-Model-as-a-Service (LMaaS), where users cannot access model parameters and gradients but can only access language models' output probability. For such a scenario, we propose the black-box tuning to optimize continuous prompts via derivative-free optimization. |
|
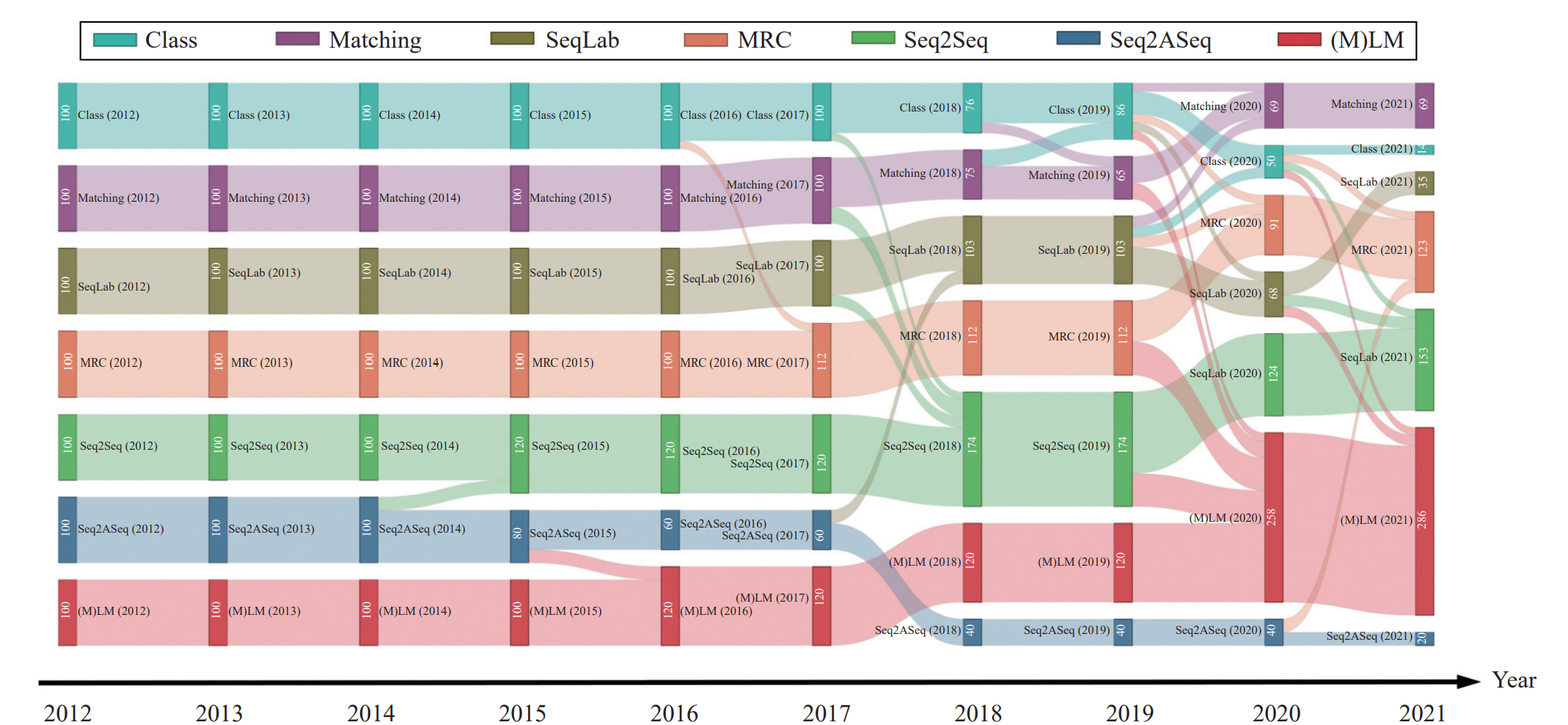
Tianxiang Sun, Xiangyang Liu, Xipeng Qiu, Xuanjing Huang Machine Intelligence Research, 2022 (Invited Paper) pdf / project / slides Recent years have witnessed a trend of paradigm shift in a variety of NLP tasks, which is to solve a task that is originally performed with a paradigm (e.g., sequence labeling) with another paradigm (e.g., machine reading comprehension). |

|
Xiangyang Liu*, Tianxiang Sun*, Junliang He, Jiawen Wu, Lingling Wu, Xinyu Zhang, Hao Jiang, Zhao Cao, Xuanjing Huang, Xipeng Qiu NAACL, 2022 (Oral Presentation) pdf / code / benchmark / slides We propose a benchmark, ELUE (Efficient Language Understanding Evaluation), for efficient NLP models and a strong baseline/backbone pre-trained model, ElasticBERT. |
|
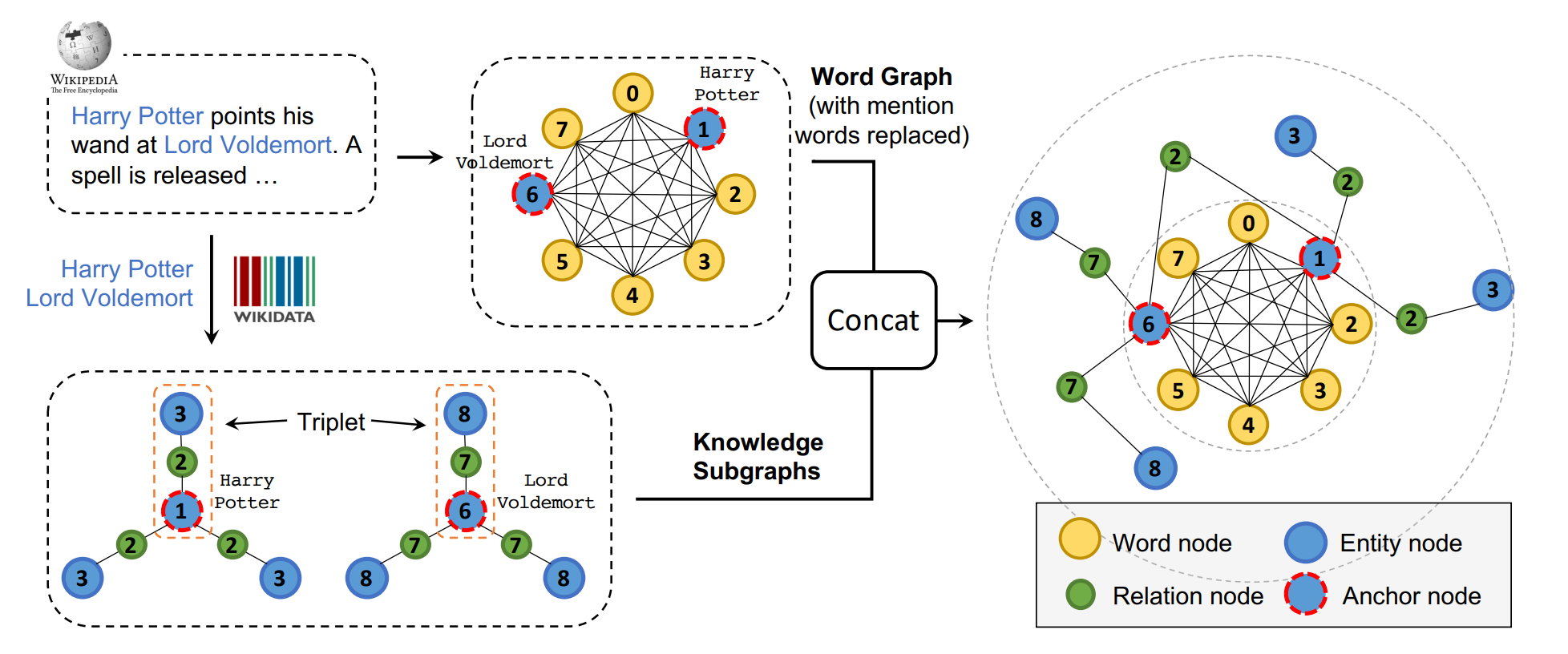
Tianxiang Sun, Yunfan Shao, Xipeng Qiu, Qipeng Guo, Yaru Hu, Xuanjing Huang, Zheng Zhang COLING, 2020 pdf / code / slides We pre-train a model called CoLAKE for jointly learning language and knowledge representation by unifying language and knowledge into word-knowledge graphs. |

|
Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, Xuanjing Huang SCIENCE CHINA Technological Sciences, 2020 (Invited Paper, Most Influential Paper of SCTS in 2020) We provide a comprehensive survey of pre-trained models (PTMs) for NLP, ranging from non-contextual word embeddings to state-of-the-art language models. This is a hands-on guide for understanding, using, and developing PTMs for various NLP tasks. |
|
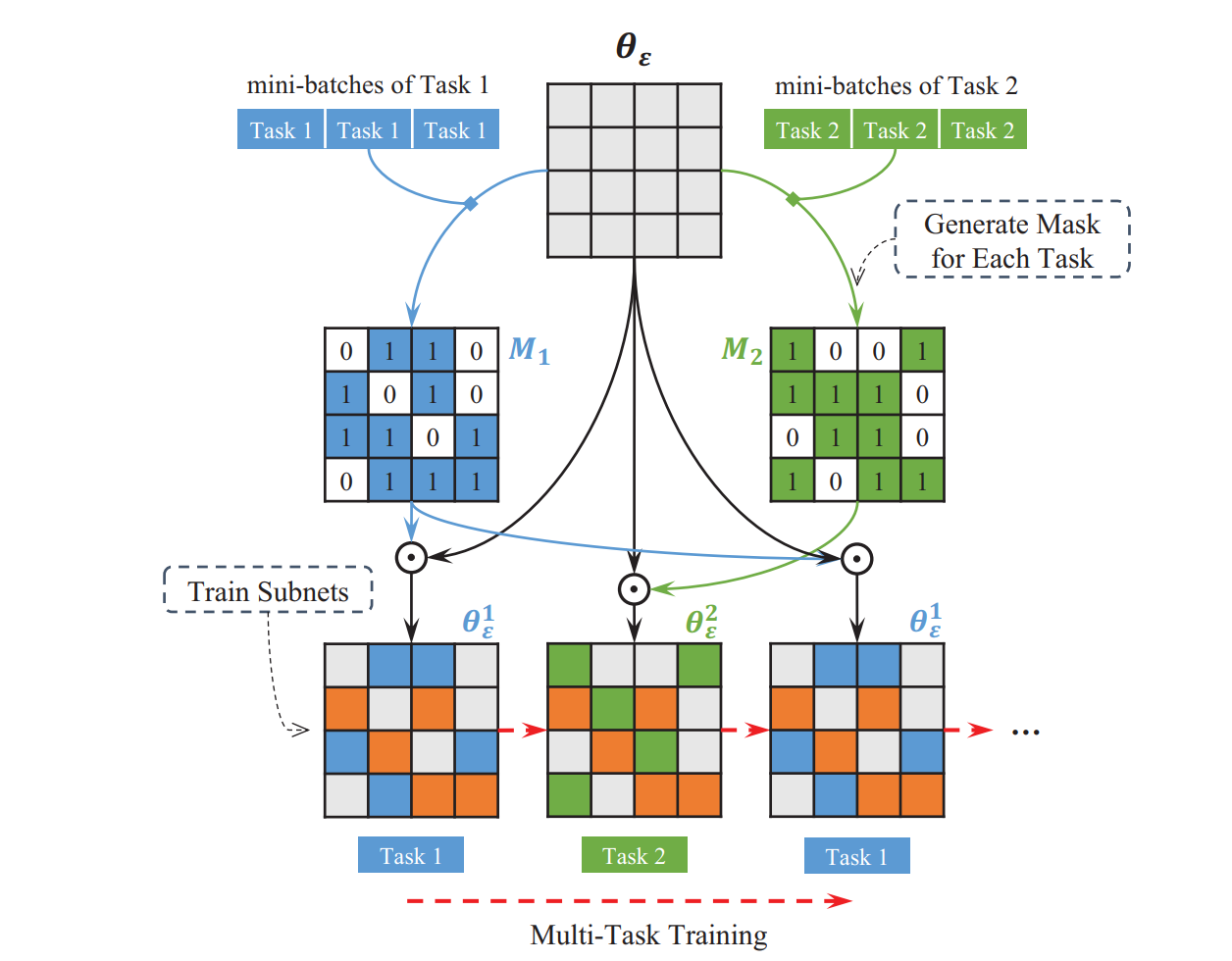
Tianxiang Sun*, Yunfan Shao*, Xiaonan Li, Pengfei Liu, Hang Yan, Xipeng Qiu, Xuanjing Huang AAAI, 2020 (Oral Presentation) pdf / code / slides We propose a new parameter sharing mechanism for multi-task learning, sparse sharing, which allocates a subnet for a task based on lottery ticket hypothesis. The sparse sharing successfully avoids negative transfer between tasks. |
|
|

|
project led by Tianxiang Sun MOSS is a conversational language model like ChatGPT. It is capable of following users' instructions to perform various natural language tasks including question answering, generating text, summarzing text, generating code, etc. MOSS is also able to challenge incorrect premises, and reject inappropriate requests. Here is a brief introduction to MOSS. |
|
maintained by Tianxiang Sun Pre-trained large language models (LLMs) such as GPT-3 are usually released as a service instead of open sourcing model weights. We call this scenario "Language-Model-as-a-Service (LMaaS)", where users can access the powerful LLMs through their inference APIs. We maintain a curated list of papers that fit into this scenario. |
|
|
Student Seminar Co-Chair
Reviewer / Program Committee Member
|
|
Design and source code from Jon Barron's website |